
When you think Hours of Operation (HOP), you probably think it’s really easy to extract this data from any website. However, you can’t even begin to imagine all the possible formats in which HOP can be presented on a website.
For example,
Mon through Fri 9 am – 5 pm,
Mon – Fri 9:00 – 17:00, Sat – Sun: 10:00 – 14:00,
Open 24h 365 days a year,
Open Dusk until Dawn
Every day 00:00-23:59
Tues./Thurs. 3-6 pm Sat./Sun. 9 a.m. -noon. & 3:00 pm- 6:00 p.m.
M – F 10-7 SA 9-6 S 11-5
And this is just the tip of the iceberg, trust us, we’ve seen some weird formats.
However, creativity liberty in HOP formats was not our only concern. Our task was to extract data from the web, meaning we were faced with all problems concerning crawling and bad HTML. Even with a mature crawling system, our crawled text sometimes had something extra or a slightly different representation from the HOP you can see on the website while using a specific browser.
HOP in our crawled text sometimes looks like this:
Days – Hours
Monday: Tuesday: Wednesday: Thursday: Friday: Saturday: Sunday: 10:00am – 6:00pm 10:00am – 6:00pm 10:00am – 6:00pm 10:00am – 6:00pm 10:00am – 6:00pm 10:00am – 6:00pm
Days and some extras
Monday: Open 24 Hours 10:00 AM – 10:00 PM Tuesday:* Open 24 Hours* 10:00 AM – 10:00 PM
Wednesday: Open 24 Hours 10:00 AM – 10:00 PM Thursday: Open 24 Hours 10:00 AM – 10:00 PM
Friday: Open 24 Hours 10:00 AM – 10:00 PM Saturday: Open 24 Hours 10:00 AM – 10:00 PM
Sunday: Open 24 Hours 10:00 AM – 10:00
Merged days
MondayFriday: 7:30 am – 4:30 pm Saturday: 8:00AM–12:00PM Sunday: Closed
Merged days & hours
Monday7:00 am – 4:00 pm Tuesday7:00 am – 4:00 pm Wednesday7:00 am – 4:00 pm
Thursday7:00 am – 4:00 pm Friday7:00 am – 4:00 pm Saturday7:00 am – 12:00 pm SundayClosed
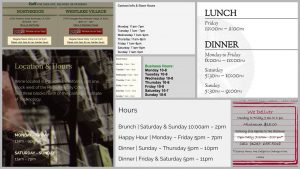
Hours of operations examples
We essentially had to be able to extract everything that human creativity can come up with, spiced up with everything that bad web representation adds (but our crawler hasn’t seen yet). But it does not end there. When you extract data, it all needs to be presented in the same format so that the company, or end-user, using this data can make quick and accurate decisions based on it. So, in addition to extraction, we must be able to standardize extracted HOPs.
And then what? Then we need a deep learning model, or more precisely – two of them: one for extraction and another one for standardization. Why? Because we also needed to be able to validate HOP. In other words, standardization would have to be independent of extraction to allow us to standardize all data input PlaceLab users sent to us for validation.
Once we have defined the problem, the data we needed, system architectures, hyperparameter to tune and different metrics to pursue, we first developed and trained our HOP extraction model. Then we dedicated our time to standardization using a dataset with 3 million HOP inputs to help our standardization model standardize even the weirdest format, as well as to cover for all extractor’s and crawler’s mistakes.
Our results were extraordinary, with nearly 100% accuracy.
When you first hear about the HOP extraction problem, it probably seems a bit boring. For us, it was anything but. NLP (Natural Language Processing) is one of the most exciting and, due to all the different specters of data locked in language, one of the most challenging fields of Machine Learning.
Developing NLP models for real-world data, especially data collected from the web, involves its own unique set of challenges. Working on HOP services, we were able to develop our own state of the art systems using the latest achievements in the field of NLP. Developing every pipeline from data generation and preparation to model deployment to production in a way that would meet all kinds of performance requirements was a very exciting, all-around NLP experience.
It’s probably why we were able to achieve such success and accuracy. Oh, and did we mention? We’re the first ones in the world to succeed in doing so.
