In this article we will discuss data accuracy and the impacts of existing gaps. With companies collecting, using, and processing large amounts of data daily, how much of this do you think is accurate?
Data accuracy is how close the data is to actual information and it is one of the components of data quality. Data can be valid but that doesn’t necessarily mean that it’s accurate. To be accurate, data must be correct and represented in a consistent and unambiguous format. If you are wondering how data can be valid but inaccurate at the same time, here is one example: two values can be, both, correct and unambiguous but still cause problems. For example, the city values ST. Clara and Saint Clara both refer to the same city. Additionally, everyone looking at values would have no trouble interpreting what values mean. However, inconsistent values could not be accurately aggregated and compared, this could create an opportunity for inaccurate usage of the data.
Accurate and consistent data is essential to business success. As the number of customer engagement channels and data sources has risen, analyzing data has become increasingly challenging. Flawed data entry processes usually result in inaccurate data entries. This can be deliberate or it can be the byproduct of system errors. When the end user applies the data in the decision making process, the problem becomes evident causing serious damage to processes and businesses.
Case study in Data Accuracy
To demonstrate how inaccurate data collection can be, we took a data sample from Open Street Map. The sample contained information about random shops and amenities in Rome, Italy.
We can divide the analysis into two segments:
- Attributes accuracy.
- Attribute validity and inconsistency.
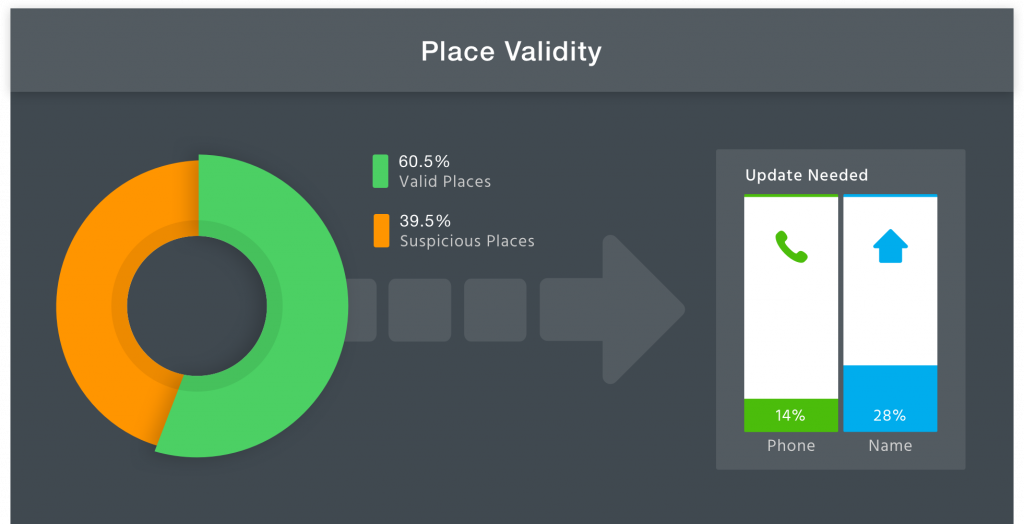
The analysis shows that 39.49% of all places are either closed or have invalid attributes since most prominent geolocation providers, such as Google, Facebook, and Foursquare, did not find these places. The subset of found places (60.5%) was further analyzed for name and phone number accuracy.
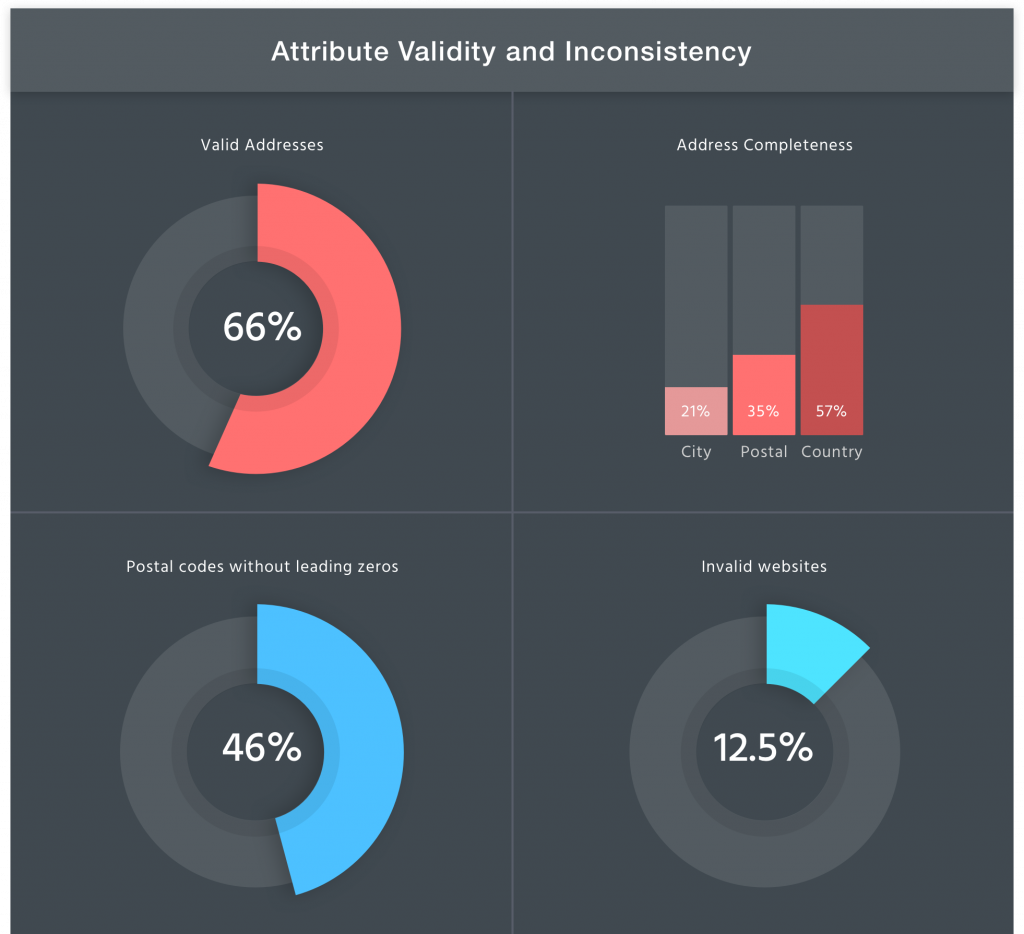
Analysis of input addresses showed that around 66% of addresses were geocoded with high precision, with a house number in the structure. The remaining 34% of input addresses are either incomplete or have inaccurate street and home number values. These addresses describe a street or intersection and anything below the street administrative level, for example city or country. Another data inconsistency was noticed during the input file analysis. It was found that 46% of the postal codes are missing the leading one or two zeros.
Further more, website activity was also checked for the entire data set and 13% of the websites are either offline or return an error.
Detailed analysis by the attribute is shown below.
Conclusion
Due to the fact that data changes constantly, at some point your data will contain a certain number of inaccurate records.
Data accuracy gaps can impact your business in a couple of ways:
- Misinformed decisions.
- Errors in product/mail delivery.
- Decreased revenue.
- Higher consumption of resources.
- Higher maintenance costs.
- Dissatisfied sales and distribution channels.
- Lower customer satisfaction and retention.
Identifying gaps in data accuracy is the first and most important step to get reliable data that can be intelligently used. If managed effectively, the obtained data can help organizations improve customer retention, streamline operations, and increase the value of each customer.
Very good information. Lucky me I came across your website by accident (stumbleupon). I have bookmarked it for later!
Thank you for your feedback. We are also exploring importance of accurate location data on advertising and small businesses. Check out our latest blog, we hope you will find it useful.
Hi there, just changed into aware of your blog via Google, and found that it is really informative. I am going to be careful for brussels. I’ll be grateful when you proceed this in future. A lot of people will be benefited out of your writing. Cheers!
Thank you for your feedback. We will continue investigating and writing about importance of accurate location data. Stay tuned!
Pretty nice post. I just stumbled upon your blog and wanted to say that I’ve really enjoyed surfing around your blog posts. In any case I will be subscribing to your rss feed and I hope you write again very soon!