
One of the biggest issues with data is the number of data errors that exist within a dataset. Even today, in the computer era, we still have extremely messy data and it is crucial to clean these errors before using it.
Even a small set of data might be imprecise, incomplete, or contain completely incorrect information – especially if we are talking about dynamic location data. Businesses open, close, change location, extend into other neighbourhoods, cities or states. Data changes over the years and it is very hard even for publishers to notice all data errors.
On the other side, companies providing data and/or data solutions to end users are collecting data from various sources. Some companies go into the field to collect fresh information on businesses, others buy data from business owners, business listings or different data aggregators, and some percentage of data providers are getting content from open source data suppliers.
In their eagerness to gather as much content as possible, data providers are combining a couple of sources and ingesting their content into the database. Although there is value in having different data origins, the quality of the data must be questioned. When working with location data, it is important to know how to find data errors and how to correct them before combining it with your data. Clean data is data that is consistent, normalized, free from duplication, and ready to have new value created from it.
In our last blog post, Try before you buy: Meeting the Supplier Challenge, we compared the quality of Foursquare and Openstreetmap data. Today, in this blog post, we are introducing government data as a source, and we will see how accurate their official data really is.
For this demonstration, we took directory information for every institution in the IPEDS universe (data.gov). The data set contained 7,770 records which we processed through the following PlaceLab quality checks:
- Duplicate detection
- Attributes verification:
- Name
- Address
- Phone number
- Website
Key findings
Our duplicates detection analysis showed that there were 80 duplicates within the data set.
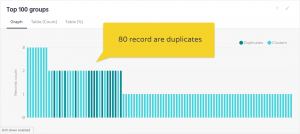
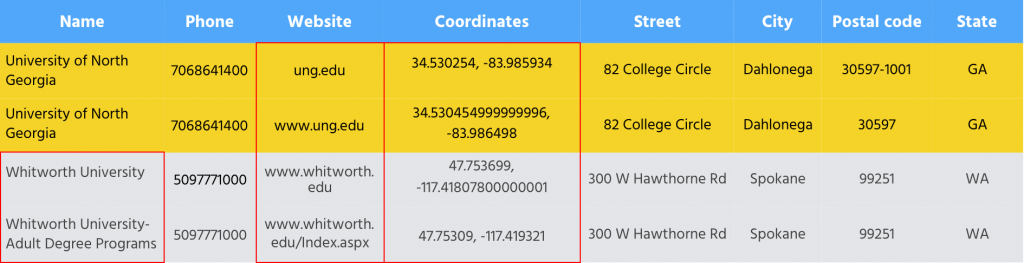
Duplicate records came into the system due to inconsistent attribute values such as different postal code formats, websites missing the prefix www, coordinates slightly moved, etc.
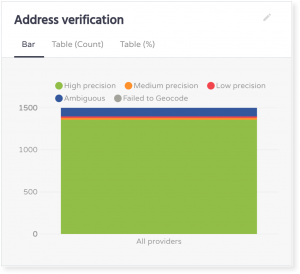
When it comes to address locations, 90% of universities have accurate and precise address values. The other 10% of addresses are either imprecise as they have address elements completed only to district or street level, or they are ambiguous to all commonly used geocoders.
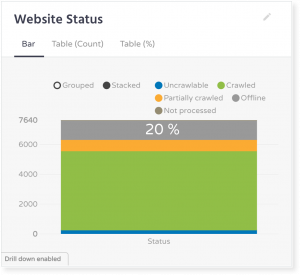
The main attributes of any business – its name and phone number values – were verified on the provided universities’ websites. Since 20% of the websites were offline, attributes verification was performed only for 80% of the records.
When compared to names found on official websites, 18% of data.gov names were either invalid or unofficial as they were extended with a city or district value.
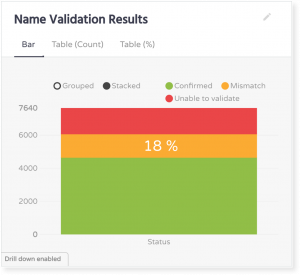

We then verified phone number values. Phone numbers could not be found on a high percentage of official websites, or to be more precise, 21% of them.
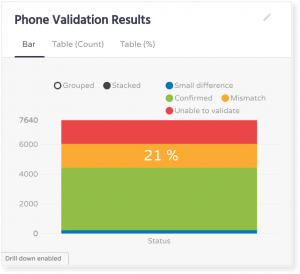
Conclusion
If you assumed that government data is clean, I hope we have proved you are wrong. Even government has messy data. It might be less messy than crowd-sourced data or any other data, but it still needs some pre-processing before ingesting it into some other system. Data inaccuracies were mostly caused by non-standardized attributes which caused duplicate records and unofficial name values.
As we said at the beginning of this blog post: It is important to know all the potential data errors and to correct them before using the data further.
In this competitive data-driven world, data providers aim to have as much content as possible, and of course at low cost. Therefore, they are choosing different types of data suppliers. Today, providers can evaluate data before ingesting it, and it is essential for their business success that they take advantage of this opportunity and assess new data suppliers before the acquisition.
Don’t be tricked by a supplier’s price or reputation. There is no clean data, and when messy data enters your database it becomes your problem.